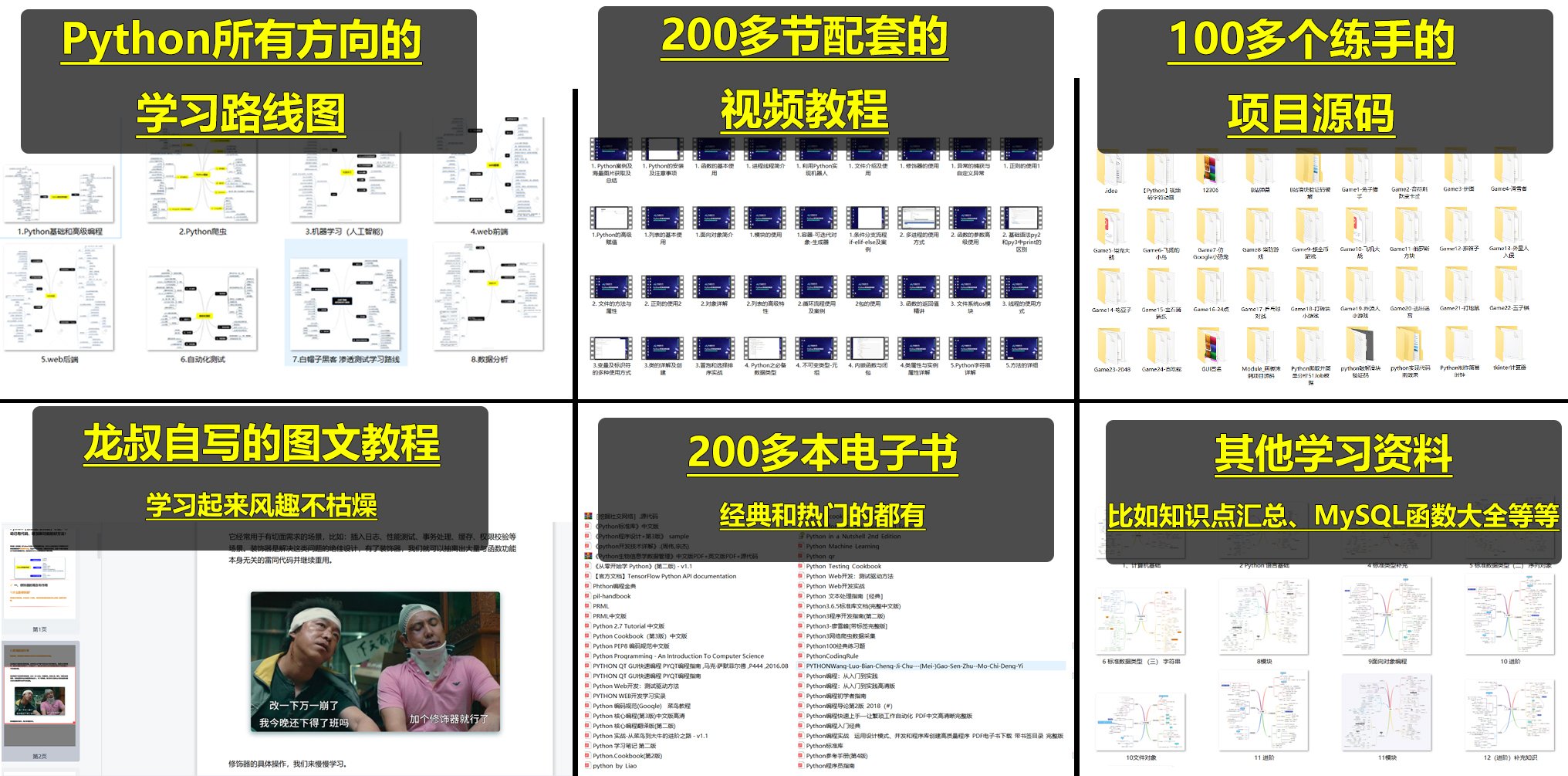
numpy
QLC
Pull APP
测试工程师
gitlab
vscode
网络攻击模型
Exception
CAS原子锁
全文检索
redis安装
web前端期末大作业
指针空值nullptr
B树
端口转发
策略模式
汇编求解一元二次方程的解
YOLOX
遗传算法
推荐
python爬虫
2024/4/12 19:16:29
从小红书app开启逆向之旅(2)
上一节课我们装了Android的开发环境,这一节课,我们动手开发一个简陋的app页面。
App逆向到底该怎么学? 从哪一步开始? Java…??? Android开发…??? 加解密…??? NDK…??? C…???
我认为应该是从lilac 的blog开始…
《python爬爬乐》入门篇:结构类型操作指南
python爬虫切片
切片就是取一个列表或元组的一部分数据。如下列表:
stockList [603477, 600876, 300792, 002800, 002552, 002351, 300078]
如果要取前两个数据, 怎么处理?
要取后两个数据,怎么处理?
如果使用传…

爬虫012_字典高级操作_查询_修改_添加_删除和清空_遍历---python工作笔记031
然后来看字典高级,首先
打印某个元素 然后打印的时候注意,如果直接打印的值,在字典中没有就报错 这里要注意不能用点访问

Python beautifulsoup解析本地文件之基础语法
视频版教程:一天掌握python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium
beautifulsoup支持解析本地文件和网络文件,需要注意的是在实例化 BeautifulSoup 对象时,“html.parser” 是一个解析器,用于解析 HTML 代码&am…
《python爬爬乐》爬虫篇:爬虫对应知识点全梳理
前言
网络爬虫,本质就是数据采集器,主要作用是模拟人工浏览网络数据的方式,把满足一定规则的数据保存到本地。从本章开始,我们就以python来实现爬虫功能,从基本的爬虫原理,到实际中的爬虫应用,…

如何从文本数据中提取子列表
提取文本数据中的子列表可以通过各种方式实现,具体取决于文本数据的结构和提取子列表的条件。例如:使用字符串操作和条件判断、使用正则表达式、使用自然语言处理工具、使用自定义解析器等几种模式,那么对于在日常使用中会有那些问题呢 &…

使用 pyparsing 的部分求解
当我们在使用 pyparsing 模块进行解析时,这就需要我们定义语法规则并编写相应的解析器。以下是一个简单的示例,演示如何使用 pyparsing 解析一个简单的算术表达式并计算其结果,以及我们经常遇到的一些问题解决方案。 1、问题背景
需要能够解…

python爬爬乐——目录
花了近两个月的时间,整理了一份爬虫相关的学习目录,后期先根据这个目录来更新博客。
总体内容分为三大块:python入门、python进阶、python爬虫。
一、python入门
包含七个知识链:
第一章:Python简介,包…

《python爬爬乐》爬虫篇:超短线量化交易需求分析及功能设计
前言
随着网络的普及,人们炒股已经不用再天天跑到证券大厅去看数据了,包括很多分析的数据,现在也可以直接通过互联网直接获取。“问财”就是这么一个专业A股数据提供网站。 通这该网站,我们可以查看今天或本周或本月或本年&#…
为什么我不推荐任何人用C语言作为编程启蒙第一课?
前言
写了20多年的代码,之前做过阿里的高级架构师,在技术这条路上跌跌撞撞了很多,我今天分享一些我个人的自学方法给各位。为什么我会说:不推荐任何人用C语言作为编程启蒙第一课?
这里有很多同学要站出来说了&#x…
《python爬爬乐》入门篇:Python简介
前言
学任何知识一定有个能在短期内快速上手的方法。并且,学习应该是快乐的,才能让人乐此不疲,而Python语言刚好满足了这两个条件,Python几乎可以做任何事情,Python的语法决定了使用它来入门编程可以事半功倍。
本系…
Python selenium无界面headless
视频版教程:一天掌握python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium
Chrome-headless 模式, Google 针对 Chrome 浏览器 59版 新增加的一种模式,可以让你不打开UI界面的情况下使用 Chrome 浏览器,所以运行效果与 …
【GUI开发】用python爬YouTube博主信息,并开发成exe软件
文章目录 一、背景介绍二、代码讲解2.1 爬虫2.2 tkinter界面2.3 存日志 三、软件演示视频四、说明 一、背景介绍
你好,我是马哥python说,一名10年程序猿。
最近我用python开发了一个GUI桌面软件,目的是爬取相关YouTube博主的各种信息&#…
Python selenium交互
视频版教程:一天掌握python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium
selenium可以模拟用户点击事件,以及控制浏览器前进,后退等操作。
下面是一个模拟百度搜索,点击下一页,控制浏览器后退,…
《python爬爬乐》入门篇:语法基础和编码规范
python爬虫这一篇有点枯燥,如果现在没兴趣或看不下去,也没关系,在后面的编程中,我们会反复使用这些基础语法。另外,下面讲的这些内容也没有必要死记硬背,知道有这些东西就行,以后用得多了&#…
Python selenium获取元素信息
视频版教程:一天掌握python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium
主要text属性和三个方法get_attribute(),get_property(),get_dom_attribute()
text属性获取元素的文本信息;
get_attribute(),ge…
Python selenium元素的定位
视频版教程:一天掌握python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium
对象的定位应该是自动化测试的核心,要想操作一个对象,首先应该识别这个对象。一个对象就是一个人一样,他 会有各种的特征(属性&…
Python selenium模块简介
视频版教程:一天掌握python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium
有些网站的数据是js动态渲染的,我们无法通过网页源码直接找到数据,只能通过找接口方式来获取数据,但是很多时候,数据又是json格式的…
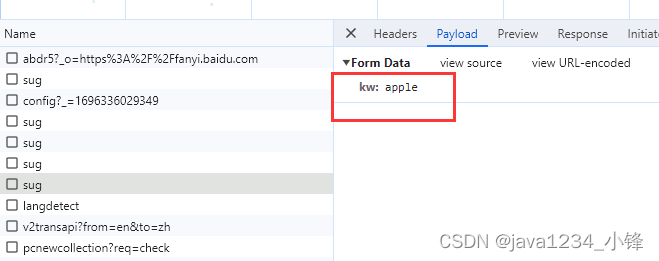
requests之post请求实例-百度翻译
视频版教程:一天掌握python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium
打开百度翻译网址,我们输入需要翻译的英文,谷歌 F12 打开开发者工具,network可以看到网络请求,我们需要找到请求的API,…
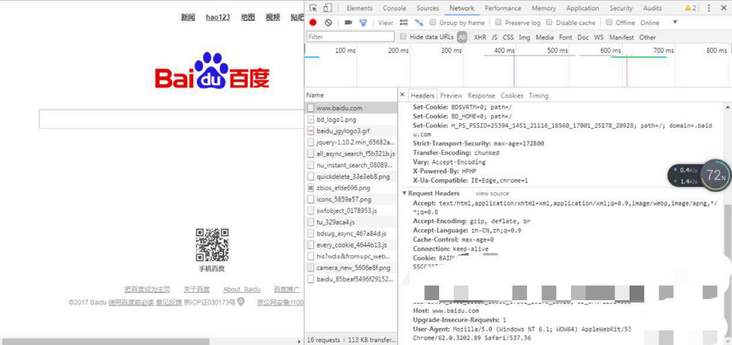
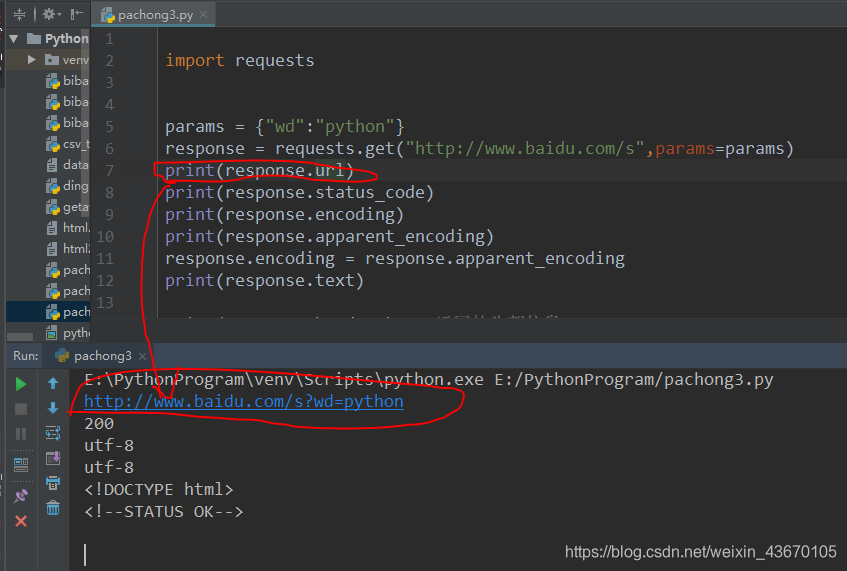
requests之get请求实例-百度搜索
视频版教程:一天掌握python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium
百度搜索请求地址:
https://www.baidu.com/s?wd宝马
如果我们直接用requests.get()进行访问,发现没有返回内容,因为百度服务器通过headers头…
Python beautifulsoup模块简介及安装
视频版教程:一天掌握python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium
简单来说,Beautiful Soup 是 python 的一个库,最主要的功能是从网页抓取数据。官方解释如下:
Beautiful Soup 提供一些简单的、python 式的函…
《python爬爬乐》入门篇:函数和函数式编程
python爬虫前言
所谓函数,就是把需要反复使用的一段代码放在一起,然后再取个名字,后面通过这个名字就能够调用这一段功能。
现实生活中,我们会把一些常用的功能做成工具,方便以后反复使用。比如煮饭,淘好…
《python爬爬乐》入门篇:结构类型详解
python爬虫字典
python中的字典(dict),来源于生活中的目录。它的主要特征,不是根据位置来访问数据,而是根据一个预先约定好的关键字(key)来访问指定数据(value),键和值使用“key : value”的方式来保存,可以称之为键值…

从小红书app开启逆向之旅(1)
上一课我们通过JustTrustMe Xposed的方式禁止了小红书的SSL 证书验证,这一节课开始,我们正式开始撸小红书。
什么自动化测试工具 什么Appium…… 什么AirTest…… 什么selenium…… 什么webdriver…… 不存在的,我们就是要硬刚************…
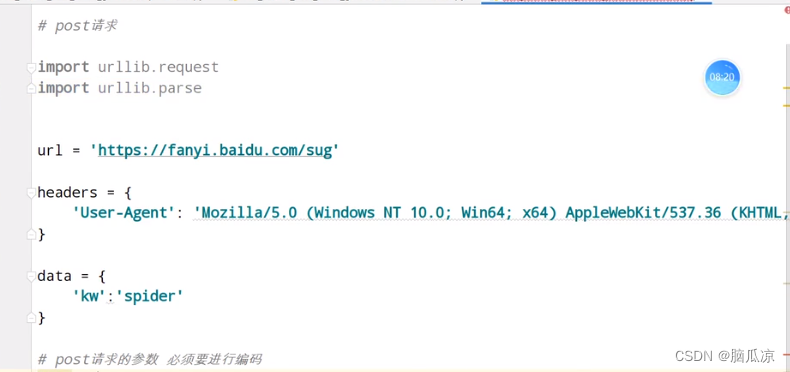
爬虫018_urllib库_cookie反爬_post请求百度翻译获取百分翻译内容_以及详细翻译内容---python工作笔记037
然后我们来看如何用urllib发送post请求,这里我们
用百度翻译为例 我们翻译一个spider,然后我们看请求,可以看到有很多
找到sug这个 可以看到这里的form data,就是post请求体中的内容 然后我们点击preview其实就是
返回的实际内容 然后请求方式用的post 然后我们把上面的信息…

密码学在Android加密中的应用和实践——MD5(1)
上一节课我们介绍说——加解密是App逆向分析,Js逆向中都十分重要和不可或缺的一部分,所以我们有必要从一个整体的、俯视的角度去了解Android中的加解密算法。这节课我们来具体的验证和学习它。我们讲解的第一个加解密算法是MD5算法。
一.什么是MD5 MD5消…
《python爬爬乐》入门篇:数据类型和变量
python爬虫
前言
学任何一门语言,都需要先了解它的基础语法,任何语言的基础语法都包括两个部分,一是数据的存储,二是数据的操作处理。
就像学中文一样,先学习拼音、再学习声调、再掌握偏旁部首,就把基础…

PyQt4应用程序的PDF查看器
最近因为项目需要创建一个基于PyQt4的PDF查看器应用程序,正常来说,我们可以使用PyQt4的QtWebKit模块来显示PDF文件。那么具体怎么实现呢 ?以下就是我写的一个简单的示例代码,演示如何创建一个PyQt4应用程序的PDF查看器:…
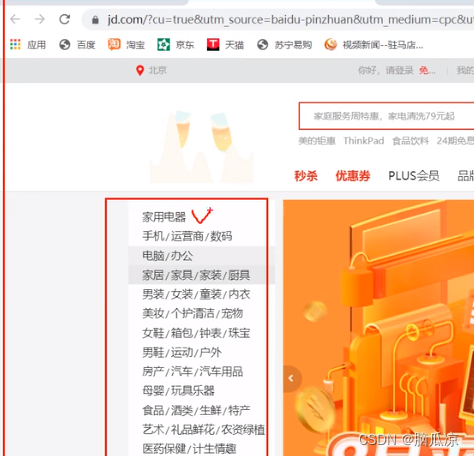

起薪2万的爬虫工程师,Python需要学到什么程度才可以就业?
爬虫工程师的的薪资为20K起,当然,因为大数据,薪资也将一路上扬。那么,Python需要学到什么程度呢?今天我们来看看3位前辈的回答。
1、前段时间快要毕业,而我又不想找自己的老本行Java开发了,所以面了很多P…
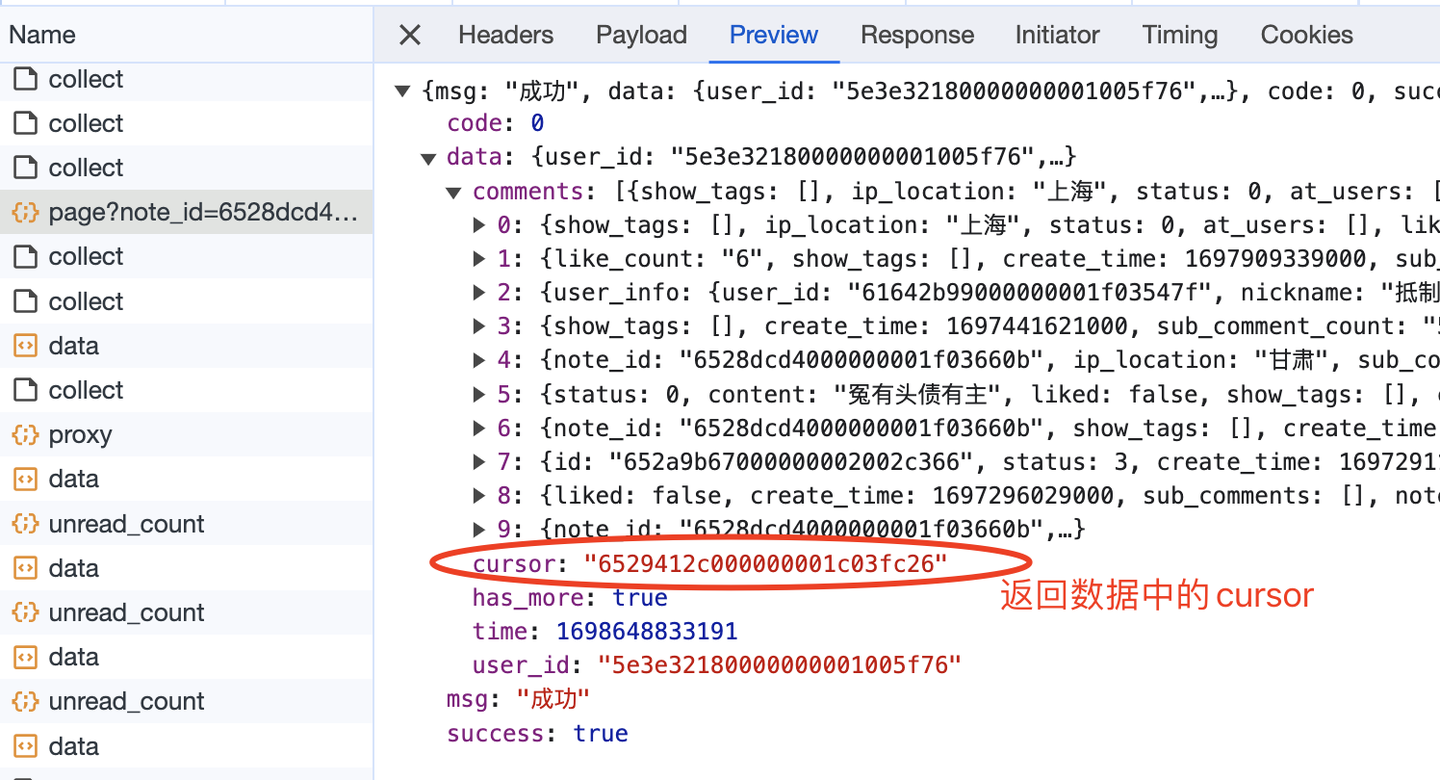
【爬虫实战】用Python采集任意小红书笔记下的评论,爬了10000多条,含二级评论!
文章目录 一、爬取目标二、爬虫代码讲解2.1 分析过程2.2 爬虫代码 三、演示视频四、附完整源码 一、爬取目标
您好!我是马哥python说 ,一名10年程序猿。
我们继续分享Python爬虫的案例,今天爬取小红书上指定笔记("巴勒斯坦…

爬虫实例爬取微信公众号文章
网站:http://weixin.sogou.com/weixin?type2&querypython&page1
实例中含有IP代理池!import requests, re, pymongo, timefrom fake_useragent import UserAgentfrom urllib.parse import urlencode
from pyquery import PyQuery
from requests…
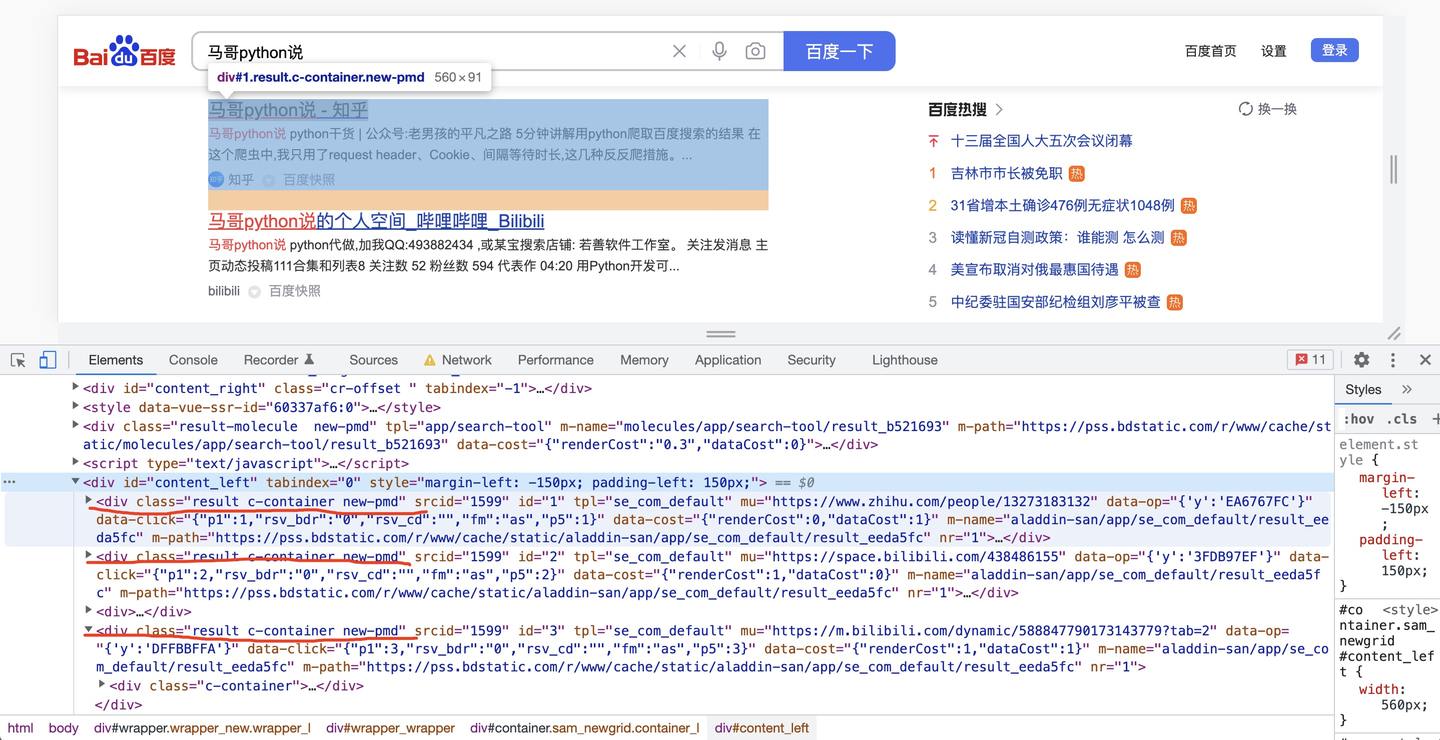
【python爬虫实战】用python爬百度搜索结果!2023.3发布
文章目录 一、爬取目标二、展示结果数据三、编写爬虫代码3.1 请求头和cookie3.2 分析请求地址3.3 分析页面元素3.4 获取真实地址3.5 保存结果数据 四、同步讲解视频五、附完整源码 一、爬取目标
本次爬取目标是,百度搜索结果数据。以搜索”马哥python说“为例&…
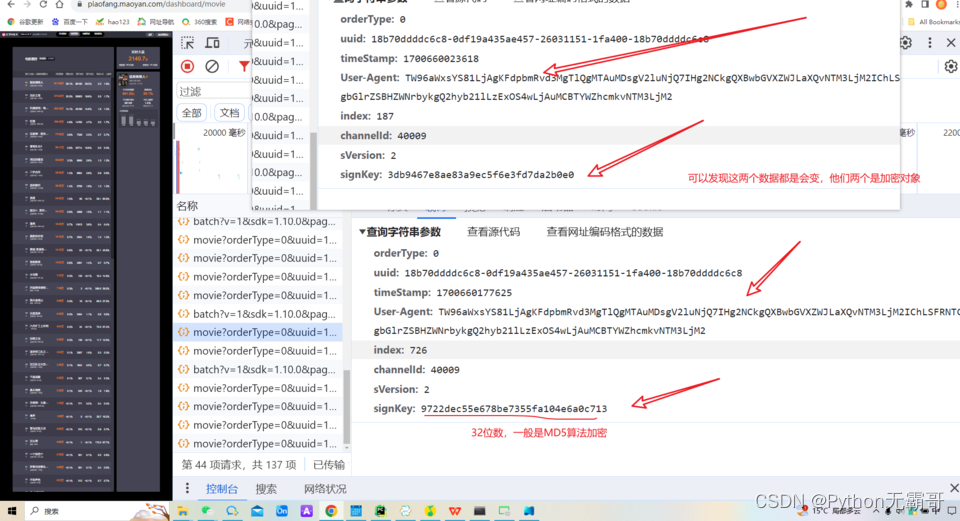
【爬虫逆向】Python逆向采集猫眼电影票房数据
进行数据抓包,因为这个网站有数据加密 !pip install jsonpathCollecting jsonpathDownloading jsonpath-0.82.2.tar.gz (10 kB)Preparing metadata (setup.py) ... done
Building wheels for collected packages: jsonpathBuilding wheel for jsonpath (setup.py) .…

Python爬虫+数据清洗+数据可视化基础案例
文章目录前言获取并筛选数据数据可视化(词云形式,激动ヾ(✿゚▽゚)ノ)编程之外前言 最近迷上了Python爬虫,我们的hadoop课程也正好涉及到了这个内容,所以就想结合课程内容(爬取京东手机评论https:…
Python requests之代理
视频版教程:一天掌握python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium
很多网站和应用都有反爬虫策略,我们频繁的访问,一旦触发反爬虫策略,我们的IP就会被封掉。
我们为了应对反爬虫,可以使用代理。
代…
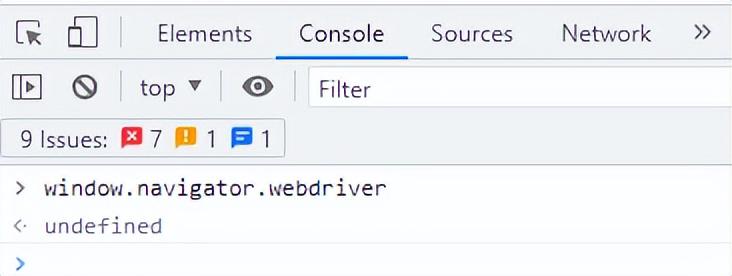
2023爬虫学习笔记 -- selenium反爬虫操作(window.navigator.webdriver属性值)
一、无可视化浏览器操作1、导入需要的函数,固定写法,并设置相关浏览器参数from selenium.webdriver.chrome.options import Options浏览器设置Options()
浏览器设置.add_argument("--headless")
浏览器设置.add_argument("--disable-gpu&…

【爬虫系列】Python 爬虫入门(1)
爬虫说明
我们知道,互联网时代,大量的数据信息会以网页作为载体而存在,有些公开而免费的数据比较适合采集,并经过有效处理之后,可用于数据分析、机器学习、科学决策等方面,而从网页中采集数据的利器&#…

【Python自动化】定时自动采集,并发送微信告警通知,全流程案例讲解!
文章目录 一、概要二、效果演示三、代码讲解3.1 爬虫采集行政处罚数据3.2 存MySQL数据库3.3 发送告警邮件&微信通知3.4 定时机制 四、总结 一、概要
您好!我是马哥python说,一名10年程序猿。
我原创开发了一套定时自动化爬取方案,完整开…

【pyspider】爬取ajax请求数据(post),如何处理python2字典的unicode编码字段?
情景:传统的爬虫只需要设置fetch_typejs即可,因为可以获取到整个页面。但是现在ajax应用越来越广泛,所以有的网页不能用此种爬虫类型来获取页面的数据,只能用slef.crawl()来发起http请求来抓取数据。
直接上例子: 可以…
听说你还不知道什么是python?本文将带你发掘python的魅力并让你爱上他
文章目录 前言什么是pythonpython的由来我们为什么要学习python帮助python学习的网站总结 前言
各位朋友们,大家好。龙叔我后台经常收到私信问什么是Python?有必要学习这门语言么?今天,将通过本文告知大家Python是什么࿱…

requests+正则表达式爬猫眼电影TOP100
爬取地址:http://maoyan.com/board/ 提示:很抱歉,您的访问被禁止 需要伪装浏览器,在headers中添加’User-Agent’字典内容 headers {User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like…
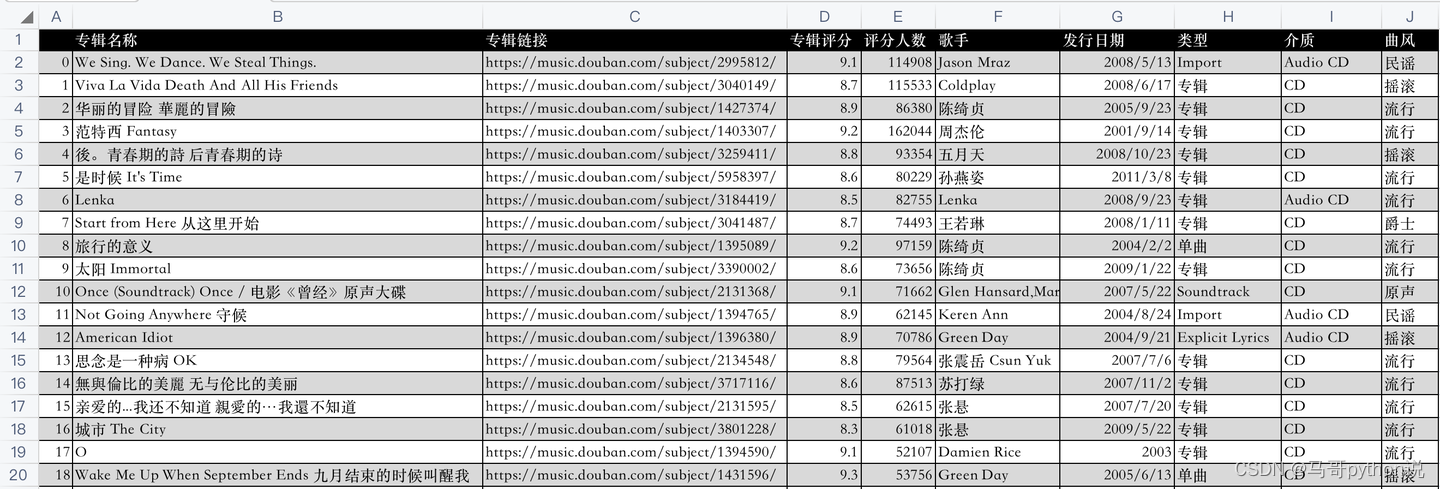
【python爬虫案例】用python爬豆瓣音乐TOP250排行榜!
文章目录 一、爬虫对象-豆瓣音乐TOP250二、python爬虫代码讲解三、同步视频四、获取完整源码 一、爬虫对象-豆瓣音乐TOP250
您好,我是 马哥python说 ,一名10年程序猿。
今天我们分享一期python爬虫案例讲解。爬取对象是,豆瓣音乐TOP250排行…
Python requests之Cookie
视频版教程:一天掌握python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium
在某些需要登录的网站或者或者应用,假如我们需要抓取登录后的内容,技术上本质通过session会话实现。服务器端存会话信息,浏览器通过Cookie携带…

Python 正则表达式之爬取古诗文名句
Python 正则表达式之爬取古诗文名句
概述: 山有木兮木有枝,心悦君兮君不知。概念介绍:
正则表达式:正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字…

Python爬虫:全国大学招生信息(二):生源数据分析(matplotlib)
在上一篇博客(https://blog.csdn.net/qq_39192827/article/details/87136836)中爬取了6W条json数据,接下来通过2D可视化来分析这些数据。需要使用的是matplotlib模块。
之前我们获取了一个大学名字对应url的txt,通过大学名字去6w…
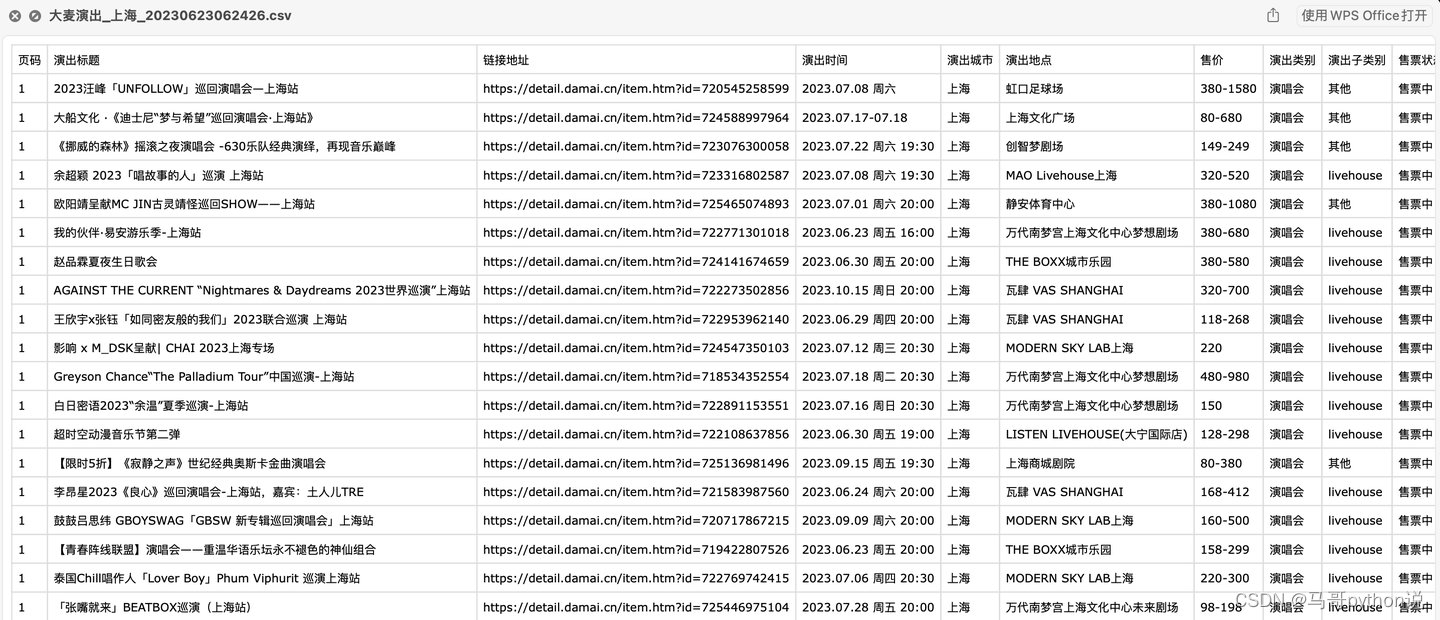
【Python爬虫案例】爬取大麦网任意城市的近期演出!
老规矩,先上结果: 含10个字段: 页码,演出标题,链接地址,演出时间,演出城市,演出地点,售价,演出类别,演出子类别,售票状态。 代码演示…
Python爬虫-抓取当当网指定图书信息,并存储到excel文件
# url -- 页面 -- 内容(分析)
import requests from lxml import html import math # 页面个数的获取 from book import Book import xlwt # 用来给excel进行写内容的 补充: 1-添加表头(书名,售价,作者) 2-每一列的…
一个暑假,用这8个高效学习方法,让我彻底掌握Python
方法的话,可以尝试这样做:
1.收集
收集各种Python相关的入门资料
网页版本、PDF版本、书籍、视频、公众号等等
推荐资源:
计算机科学速成课:https://www.bilibili.com/video/BV1EW411u7th计算机网络微课堂:https:…
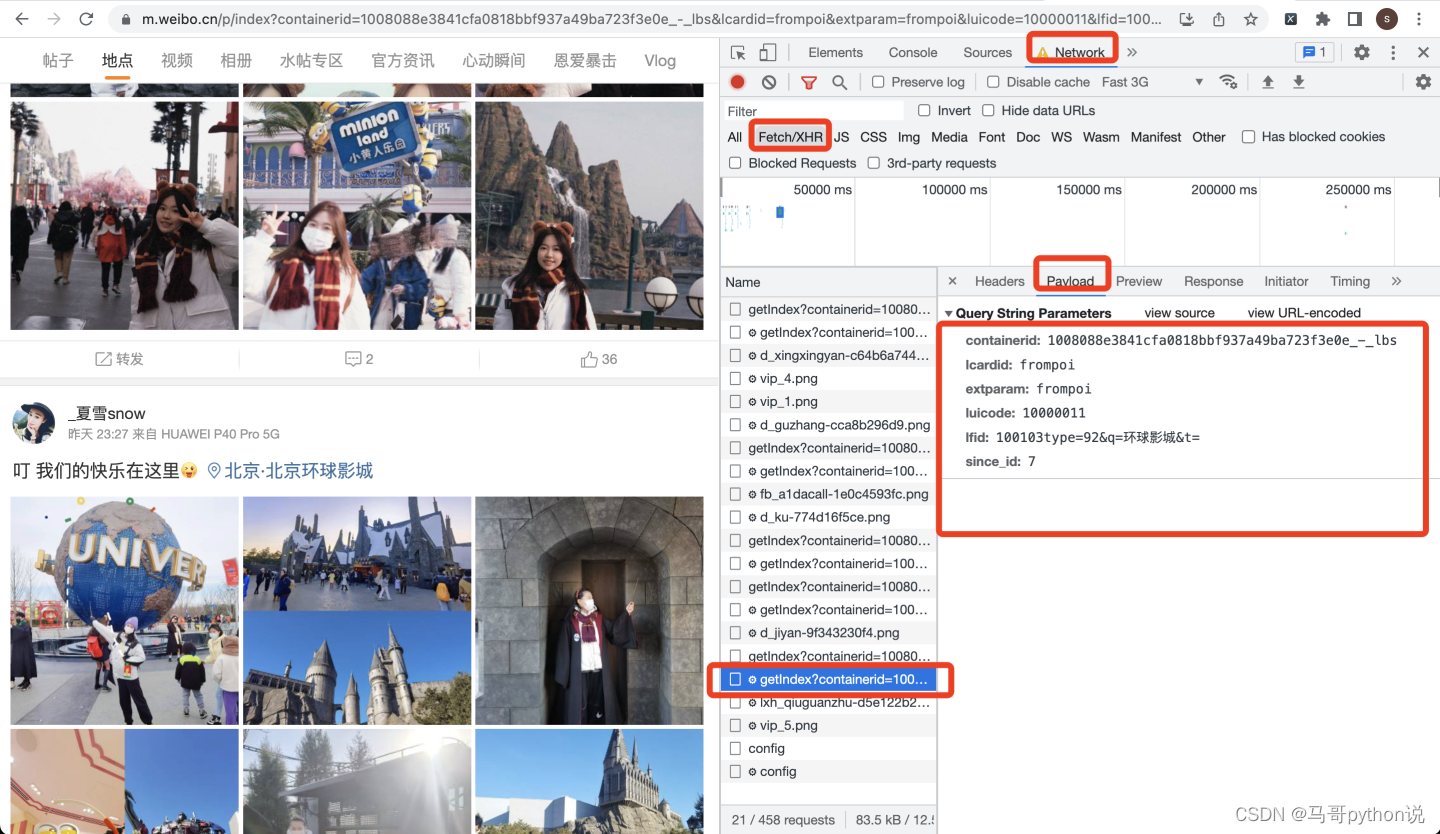
【python爬虫案例】爬了上千条m端微博签到数据
一、爬取目标
大家好,我是马哥python说,一枚10年程序猿。
今天分享一期python爬虫案例,爬取目标是新浪微博的微博签到数据,字段包含: 页码,微博id,微博bid,微博作者,发布时间,微博内容,签到地点,转发数,评论数,点赞数…

python爬虫获取携程旅游景点评分和评论
写在前面:酒店和旅游景点方式不同,不能用我的写法,如果获取酒店数据请参考:https://blog.csdn.net/qq_34774456/article/details/89885296
旅游景点代码(地址要用手机版的携程搜自己想搜的景点)࿱…
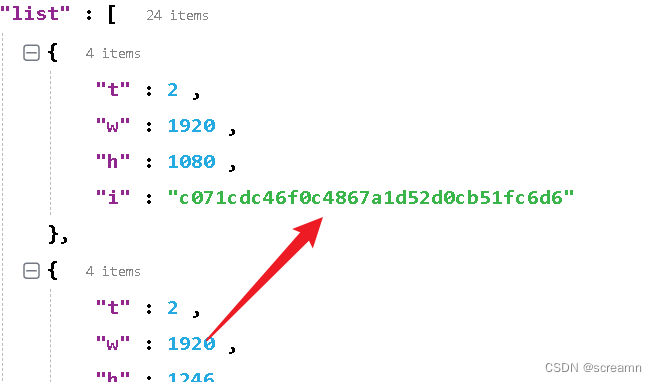
极简壁纸js逆向(混淆处理)
本文仅用于技术交流,不得以危害或者是侵犯他人利益为目的使用文中介绍的代码模块,若有侵权请练习作者更改。
之前没学js,卡在这个网站,当时用的自动化工具,现在我要一雪前耻。
分析
第一步永远都是打开开发者工具进…

python爬虫系列--小练爬取花田首页源码
import requests#step1 指定url
urlhttps://love.163.com/ #step2 发送GET请求
responserequests.get(urlurl)#step3 获取响应数据,text:字符串格式
page_coderesponse.text
with open(youtian.html,w,encodingutf-8) as fp:fp.write(page_code)
print(爬取源码…
Python网络爬虫实战项目大全!
学习Python主要是爬取各种数据,进行数据分析,获得各种有意思的东西。今天我们就来做些Python网络爬虫实战项目,包含微信公号、豆瓣、知乎等网站爬虫,大家也要自己动手练练看呀。WechatSogou - 微信(http://lib.csdn.ne…
用yolov5识别点选验证码中的目标内容
目录
获取训练所需的图片
训练模型
总结与提高
源码下载 如果要过掉点选验证码,首先就要获取目标点选内容的坐标位置,我们可以训练一个yolov5模型来实现这一功能。在本节,我们拿凯格行为验证码来进行演示,验证码图片如下所示。
Re正则匹配和Python初级爬虫学习心得
以下是个人对正则匹配、爬虫的一点学习心得,分享给大家,相互学习,有错误请指出,谢谢!
如果用Python写爬虫的话,正则匹配在re包里面,然后一般也需要用到urllib2(网络请求响应),Beaut…
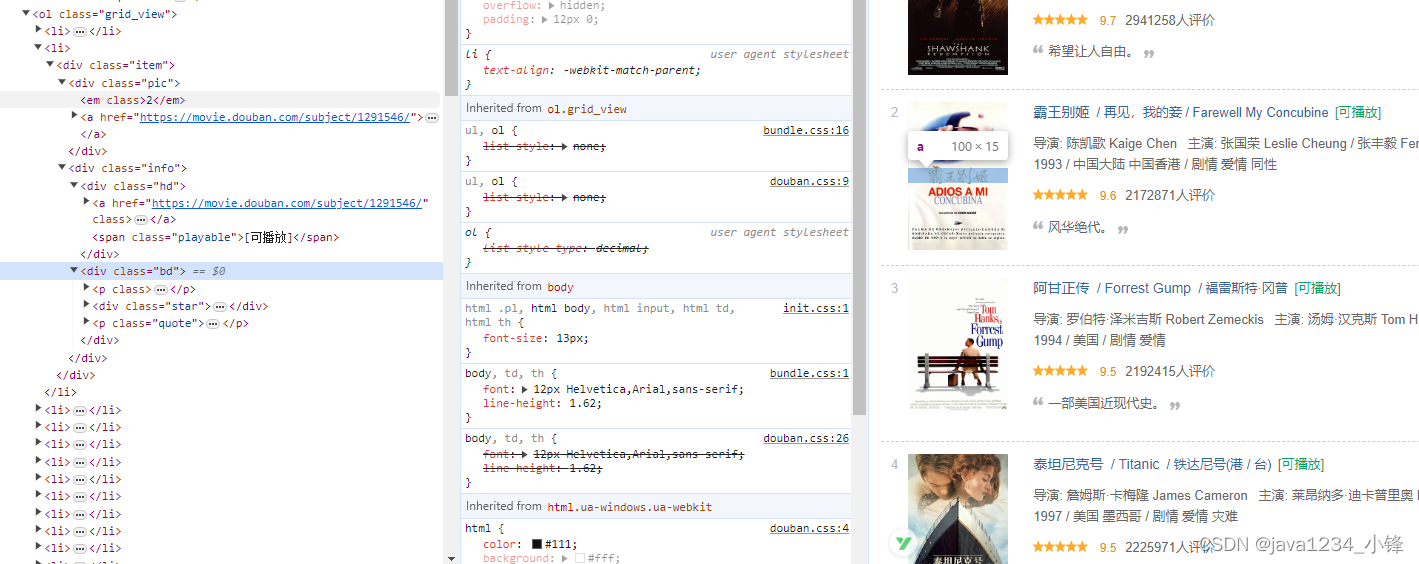
Python爬虫实战-批量爬取豆瓣电影排行信息
大家好,我是python222小锋老师。
近日锋哥又卷了一波Python实战课程-批量爬取豆瓣电影排行信息,主要是巩固下Python爬虫基础
视频版教程:
Python爬虫实战-批量爬取豆瓣电影排行信息 视频教程_哔哩哔哩_bilibiliPython爬虫实战-批量爬取豆瓣…
Python爬虫实战-批量爬取豆瓣电影排行信息
大家好,我是python222小锋老师。
近日锋哥又卷了一波Python实战课程-批量爬取豆瓣电影排行信息,主要是巩固下Python爬虫基础
视频版教程:
Python爬虫实战-批量爬取豆瓣电影排行信息 视频教程_哔哩哔哩_bilibiliPython爬虫实战-批量爬取豆瓣…
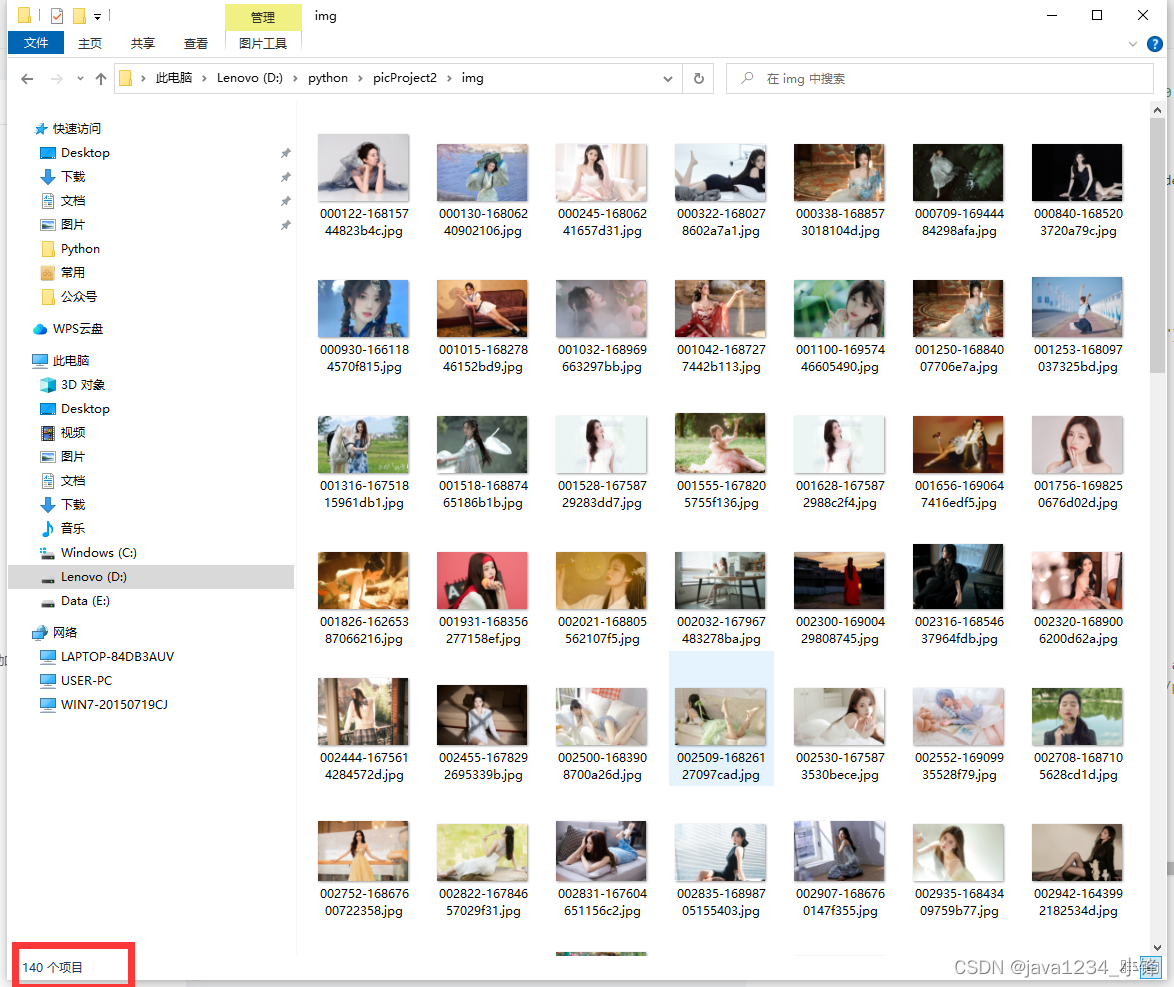
Python爬虫实战-批量爬取美女图片网下载图片
大家好,我是python222小锋老师。
近日锋哥又卷了一波Python实战课程-批量爬取美女图片网下载图片,主要是巩固下Python爬虫基础
视频版教程:
Python爬虫实战-批量爬取美女图片网下载图片 视频教程_哔哩哔哩_bilibiliPython爬虫实战-批量爬取…
Python爬虫实战-批量爬取美女图片网下载图片
大家好,我是python222小锋老师。
近日锋哥又卷了一波Python实战课程-批量爬取美女图片网下载图片,主要是巩固下Python爬虫基础
视频版教程:
Python爬虫实战-批量爬取美女图片网下载图片 视频教程_哔哩哔哩_bilibiliPython爬虫实战-批量爬取…
《python爬爬乐》入门篇:选择结构
python爬虫前言
一般程序的结构就和现实中过马路一样,有三种情况。
第一种,在高速公路上,没有一个红绿灯,一路走到底不用停。(顺序结构)
第二种,在城市街道开车,就要观察红绿灯&a…

python网络爬虫爬取西南大学官网2014年-2019年内所有通知和新闻
该博客介绍了如何使用python爬取西南大学官网2014年-2019年内所有通知和新闻的过程。使用了PyQery,re和time库,在开始爬取之前先安装这个好这3个基本库,推荐使用pip3安装,因为是从国外下载,过程可能比较慢,所以如果要学…

37张思维导图,记录纯小白五天速通Python的学习笔记
需要收藏的beginner可以加我的Python学习交流群:956331022,导图源文件放在群公告中,可直接下载!群内还有其他python相关的电子书籍与学习资源!
一、Python基础篇 二、Python函数
需要收藏的beginner可以加我的Python…

Python就该这样学,我是如何2个月快速掌握Python的!学习大纲+学习方式+学习资料 汇总!
一、学习建议
1、找到自己感兴趣的方向,并且结合市场需求进行选择 Python的应用范围 测试运维web人工智能大数据爬虫及数据分析办公自动化2、学习过程中一定要勤加练习,并且尝试去使用学习过的内容实现一些简答的功能
遇到技术问题不要慌,解…
Python selenium驱动下载,模块安装以及基本使用
视频版教程:一天掌握python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium
我们以谷歌浏览器为例讲解。首先我们要去下载谷歌浏览器驱动。
谷歌浏览器驱动下载地址:Chromium History Versions Download ↓
查看谷歌浏览器版本 右上角三个点 …

Python beautifulsoup网络抓取和解析cnblog首页帖子数据
视频版教程:一天掌握python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium
我们抓取下https://www.cnblogs.com/ 首页所有的帖子信息,包括帖子标题,帖子地址,以及帖子作者信息。
首先用requests获取网页文件࿰…

密码学在Android加密中的应用和实践——引言
加解密是App逆向分析,Js逆向中都十分重要和不可或缺的一部分,所以我们有必要从一个整体的、俯视的角度去了解Android中的加解密算法。
我始终认为,逆向技术离不开对正向开发的深度了解,Xposed中一些已有的自吐算法模块可以让人快…

13天搞定python分布式爬虫(视频+项目双管齐下)
前言
13天搞定python分布式爬虫(视频项目双管齐下)(文末送福利)
学习python爬虫首先要清楚您当前的技术基础,如果是零基础的话可能需要花1-2个月的左右补充python基础,如语法、函数、用库、面向对象等等……
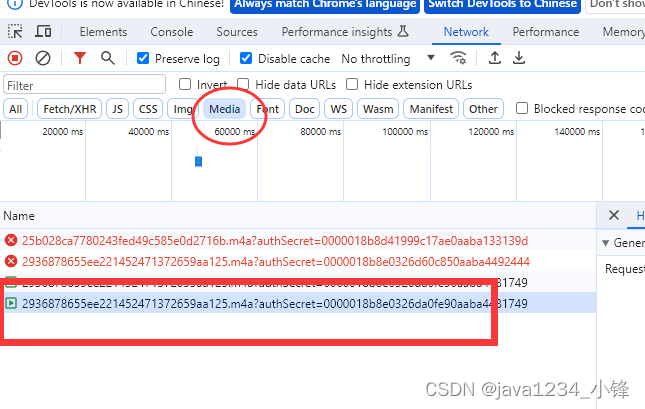
Python爬虫实战-批量爬取下载网易云音乐
大家好,我是python222小锋老师。前段时间卷了一套 Python3零基础7天入门实战https://blog.csdn.net/caoli201314/article/details/1328828131小时掌握Python操作Mysql数据库之pymysql模块技术https://blog.csdn.net/caoli201314/article/details/133199207一天掌握p…
Python爬虫实战-批量爬取下载网易云音乐
大家好,我是python222小锋老师。前段时间卷了一套 Python3零基础7天入门实战https://blog.csdn.net/caoli201314/article/details/1328828131小时掌握Python操作Mysql数据库之pymysql模块技术https://blog.csdn.net/caoli201314/article/details/133199207一天掌握p…
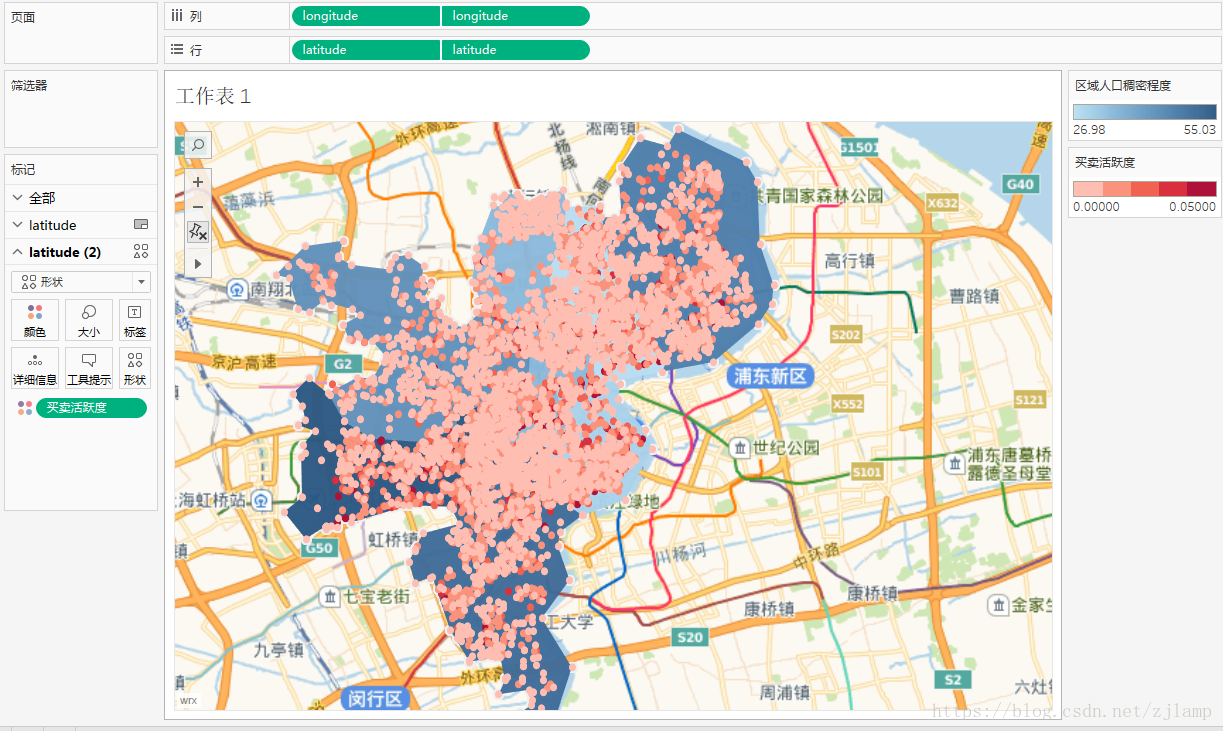
利用Python爬虫和Tableau分析链家网二手房信息
1、明确分析的目标和思路
目的:近年来,房价时时刻刻牵动着广大老百姓的心,尤其是急需买房的刚需族和二胎家庭的置换族。本文希望通过对上海市中心城区二手房信息的分析,能够对房价和地理位置、房龄等因素的关系有一定的掌握。
分…

Python兼职接单(非常详细)从零基础入门到精通,看完这一篇就够了
当下python需求量还是挺大的,对于想要做兼职的程序员还是挺友好的:起码不用愁找不到;目前来看,其兼职方向大致有三:开发、爬虫、数据分析。
就开发来说,目前python的轮子在Github上一抓一大把,…
写给小白,Python 爬虫学习思路
爬虫是Python是一个很经典的方向,大多数的小伙伴看到的是Python爬虫的就业效果,确实Python爬虫学习成本低(学习快),就业效果好,特别适合新手入门,但是也要关注另外一个点,就是Python…
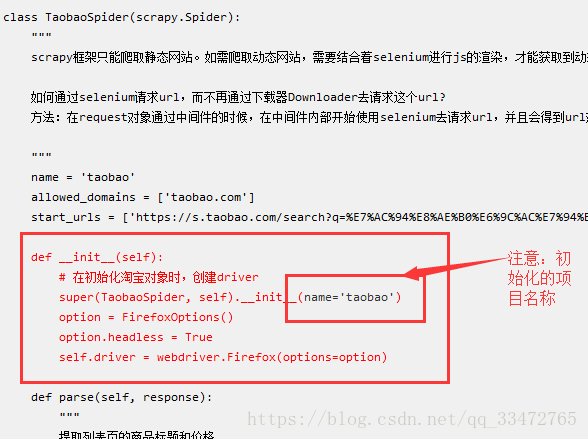
Python爬虫scrapy框架爬取动态网站——scrapy与selenium结合爬取数据
scrapy框架只能爬取静态网站。如需爬取动态网站,需要结合着selenium进行js的渲染,才能获取到动态加载的数据。如何通过selenium请求url,而不再通过下载器Downloader去请求这个url?
方法:在request对象通过中间件的时候࿰…

Python脚本处理unicode字符时的解决方法
我们在Python中,可以使用Unicode编码来表示字符。Unicode是一种字符集,它为世界上几乎所有的字符都分配了一个唯一的数字,这个数字被称为码点。在Python中,在使用Unicode字符出现的问题又该如何解决? 1、问题背景
在编…

【python】websocket原理详细剖析,如何使用python爬取ws协议数据?
✨✨ 欢迎大家来到景天科技苑✨✨
🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,阿里云开发者社区专家博主,CSDN新星创作者,掘金优秀博主,51CTO博客专家等。 🏆《博客》:Python全栈,前后…
Python爬虫学习之-从零开始
大家好,相信点进来看的小伙伴都对爬虫非常感兴趣,博主也是一样的。博主刚开始接触爬虫的时候,就被深深吸引了,因为感觉SO COOL啊!每当敲完代码后看着一串串数据在屏幕上浮动,感觉很有成就感,有木…
playwright下载及基本使用
playwright下载及基本使用 1. 下载playwright库2. playwright使用2.1导入库2.2 基本使用 3.XPATH元素定位方法3.1 xpath定位语法3.2 相关操作 4. 等待及缓存4.1 等待操作4.2 添加缓存 1. 下载playwright库
pip install playwright1.33.0
playwright install 2. playwright使用…
爬虫Python入门好学吗?学什么?
爬虫Python入门好学吗?学爬虫需要具备一定的基础,有编程基础学Python爬虫更容易学。但要多看多练,有自己的逻辑想法。用Python达到自己的学习目的才算有价值。如果是入门学习了解,开始学习不难,但深入学习有难度&#…
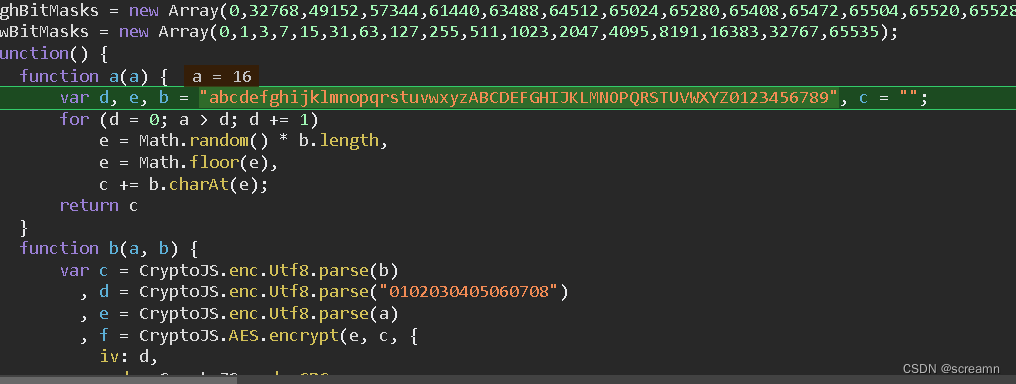
逆向获取某音乐软件的加密(js逆向)
本文仅用于技术交流,不得以危害或者是侵犯他人利益为目的使用文中介绍的代码模块,若有侵权请联系作者更改。
老套路,打开开发者工具,直接开始找到需要的数据位置,然后观察参数,请求头,cookie是…
爬虫requests库
爬虫requests库
requests是python的一个很实用的HTTP客户端库,完全满足如今网络爬虫的需求,具备Urilib的全部功能。完全兼容python2和python3,具有较强的适用性。
1.windows下的安装
pip install requests2.requests库的7个主要方法&#…
requests模块简介及安装
视频版教程:一天掌握python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium
Requests是一个优秀的Http开发库,支持HTTP连接保持和连接池,支持使用cookie保持会话,支持文件上传,支持自动确定响应内容的编码&am…

Python爬虫实战之研招专业目录抓取(共享源码)
今天给大家分享一个实战项目,利用 Scrapy 框架抓取研招网的招生目录信息。包括各个招生单位的所有招生专业信息以及考试课程信息等,最终效果如下。(相关源码等资源,可关注公众号:Python资源分享,回复 yanzh…

Python爬虫从入门到入狱系列合集
我 的 个 人 主 页:👉👉 失心疯的个人主页 👈👈 入 门 教 程 推 荐 :👉👉 Python零基础入门教程合集 👈👈 虚 拟 环 境 搭 建 :👉&…
《python爬爬乐》入门篇:结构类型之列表
python爬虫前言
现实生活中,我们会在家里摆放各种家具,用于存放不同类型的物品,比如鞋柜,衣柜,书柜,茶几、电视柜等。在python中也是一样,当使用的数据越来越多时,就需要考虑如何存…

Python爬虫第一天
1.安装BeautifulSoup库(第三方库,简化正则,目前还未体会到其应用优势~~) 2.Test1:获取url网页信息
import urllib.request
response urllib.request.urlopen(http://python.org/)
result response.read().decode(utf-8)
print…
Python爬虫第二天
1.查看淘宝网的robots.txt文档 https://www.taobao.com/robots.txt User-Agent:* Disallow:/
意思是除前面指定的爬虫外,不允许其他爬虫爬取任何数据。
2.soupBeautifulSoup(html_document)
3.今天模仿博客写了爬取网页图片链接并下载链接资源的爬虫程序…